skip to main |
skip to sidebar
 Another interesting paper at the Łódź conference was given by Włodzimierz Sobkowiak (seen with me in this photograph, taken by Alice Henderson).
Another interesting paper at the Łódź conference was given by Włodzimierz Sobkowiak (seen with me in this photograph, taken by Alice Henderson).
He started by showing us some of the appallingly improbable and stilted “English” sentences given in Polish textbooks of elementary English over the course of the twentieth century. For example, can you imagine a husband and wife ever saying this?
—Am I a man?
—Yes, you are a man, and I am a woman.
Equally improbable is that any native speaker, talking to other NSs, would come out with
The house is high.
or even
I am a teacher. I have many students.
More importantly, Sobkowiak demonstrated how many of the “elementary” example sentences in fact contain multiple points of phonetic difficulty for the Polish learners at whom they were aimed.
This is his dog.
In this simple example there are several tricky pronunciation features: the difficult consonant ð; the orthographic irregularity that final -s corresponds to s in this but to z in is and his; and not least the final g in dog (Polish devoices final obstruents).
Any sentence containing preconsonantal the is problematic — not only phonetically, with the non-Polish ð and ə, but also grammatically, since Polish has no articles.
An ideal sentence for absolute beginners, he thought, might be I like music.
This maps happily onto pseudo-Polish aj lajk mjuzyk.
Sobkowiak has identified some 61 points of phonetic difficulty for Poles in the pronunciation of English words. Using these, he has devised a Phonetic Difficulty Index (PDI) and has analysed the PDI of thousands of vocabulary items presented to Polish learners accordingly.
He reckons that the phonetically most difficult vocabulary items he encountered were authoritarians ɔːˌθɒrɪˈteəriənz, light-coloured ˌlaɪtˈkʌləd, pearl fisheries ˈpɜːl ˌfɪʃəriz, and square-shouldered ˌskweəˈʃəʊldəd. Each of these, he says, scores 11 points of difficulty.
Learners from other language backgrounds would have similar though not identical problems. (For example, English θ is a difficult consonant for speakers of Polish, but not for speakers of Castilian Spanish, Standard Arabic, or Greek.) Phonetically aware language teachers could construct a PDI for any L1-L2 pair.
_ _ _
And a happy new year to all!
This blog will again be suspended for the whole of the month of January. Next posting: 1 February 2012.
 At the Łódź conference John Coleman presented an interesting talk about the spoken component of the British National Corpus. It comprises about ten percent of the entire corpus.
At the Łódź conference John Coleman presented an interesting talk about the spoken component of the British National Corpus. It comprises about ten percent of the entire corpus.
It includes a wide range of authentic spoken material, recorded in 1991-92 by volunteers wearing Walkman devices recording all their conversational interactions over a 24-hour period. As well as all kinds of structured and unstructured talk directed at other people, from sermons to discussions of boyfriends, the files include dog-directed and parrot-directed speech. Who’s a pretty boy, then?
The material has now been digitized by the British Library from the original analogue recordings.
Although comprising only ten percent of the whole corpus, the audio material of the BNC extends to 9 TB (nine terabytes), about 1800 hours’ worth. So you won’t be downloading it all and storing it on your hard disc any time soon.
Although the whole spoken corpus is unmanageably large, a selection of audio files from the BNC is now available online.
The ten most frequently used words in the spoken corpus, Coleman says, occur more than 58,000 times each. At the other extreme, 23% of the words used (12,400 words) occur only once. Many other words that are surely in people’s vocabulary never occur at all.
Coleman presented some observations about assimilation of place of articulation. As well as the familiar dealveolar type (ˈtem ˈmɪnɪts, ˈɡʊɡ ˈɡɜːl), he found various instances of “nonstandard place assimilation of word-final /m/ and /ŋ/”. Delabial examples included siːn in seem to and seɪŋ in same kind of. As well as plenty of cases of aɪŋ(ɡ)ənə etc for I’m going to, he reports “18 tokens per 10 million” of əˈlɑːŋ klɒk for alarm clock. The most frequent item classified as develar was swimming pool pronounced as ˈswɪmɪm puːl — but there of course the underlying form of the -ing ending would be ɪn rather than ɪŋ for some speakers in some styles of speech (as the sociolinguists have documented), so that the assimilation could be dealveolar after all, not develar. The same applies to ˈwedɪm in wedding present.
We await further reports with interest.
 Yesterday’s brief mention of Brno triggered interest in its pronunciation. In Czech it is ˈbr̩no, two syllables, the first having a stressed syllabic trill. Mendel, though, being a native speaker of German, would have known it as Brünn brʏn.
Yesterday’s brief mention of Brno triggered interest in its pronunciation. In Czech it is ˈbr̩no, two syllables, the first having a stressed syllabic trill. Mendel, though, being a native speaker of German, would have known it as Brünn brʏn.
Inspired by this thought, Stephen Bryant sent me a picture of the Nový Most (‘new bridge’) in Bratislava, which I show in reduced size alongside. He adds the comment 
What I really like about this photo is the green panel on the sign, pointing to Brno, Žilina, Győr and Vienna, four cities in four countries, the Czech Republic, Slovakia, Hungary and Austria respectively.
Perhaps the pronunciation of Győr — which I for one struggle with — could be the subject of a future blog entry.
Győr is pronounced ɟ(ʝ)øːr. You can tell the name is Hungarian, since the letter ő, with its double acute accent, is used in the spelling of no other language (or at least, no other European language). The logic behind this unusual diacritic is that Hungarian uses a diaeresis, as in German, to show front rounded vowels (ö, ü), and an acute accent, as in Czech, to show vowel length (á, é, í, ó, ú): so for long front rounded vowels you have an acute diaeresis (ő, ű).
There is some debate as to how the initial consonant, orthographic gy, is best classified. All agree that it is a voiced palatal obstruent. The question is whether it is a plosive, ɟ, or an affricate, ɟʝ. The 1999 IPA Handbook treats it as an affricate, but adds this note. In formal style /cç, ɟʝ/ are realized mostly as palatal stops, i.e. [c] and [ɟ].
Its predecessor, the 1949 Principles booklet, says simply c, ɟ cardinal palatals.
Anyhow, the result is similar to the English gj in regular. The vowel is as in German schön; the final consonant is an apical tap, or in my experience may alternatively sometimes be fricative. Listen here.
Győr has a number of names in other languages: as well as nativized forms such as Дьёр in Russian and Đur or Jura in Croatian, it has the apparently unrelated name Raab in German. But as far as I am aware there is no traditional anglicized form of the name.
 I’ve been reading Siddharta Mukherjee’s fascinating book The Emperor of All Maladies. I’d go along with Dacid Rieff’s judgment:
I’ve been reading Siddharta Mukherjee’s fascinating book The Emperor of All Maladies. I’d go along with Dacid Rieff’s judgment: Siddhartha Mukherjee has done something that should not have been possible: he has managed, at once, to write an authoritative history of cancer for the general reader, while always keeping the experiences of cancer patients in his heart and in his narrative. At once learned and skeptical, unsentimental and humane, The Emperor of all Maladies is that rarest of things - a noble book.
I had not previously been aware of the importance of the German doctor and biologist Rudolph Virchow (1821–1902), who made several important discoveries to do with leukemia. Coming across his name in the book, I naturally wondered how to pronounce it. Its spelling combines three different uncertainties in German spelling-to-pronunciation rules: the initial letter v (f or v?), ch (ç or x?) and the final w (f or silent?).
Mangold’s Duden Aussprachewörterbuch gives Virchow ˈfɪrço, auch ˈvɪ…
This is confirmed by the Deutsches Aussprachewörterbuch.fˈɪʁçoː od. vˈɪʁ…
Merriam-Webster 11 offers the anglicization ˈfir-(ˌ)kō, ˈvir-
which translates into BrE as ˈfɪəkəʊ or ˈvɪəkəʊ. So be it.
_ _ _
The rest of this post is a rant about the failure of authors and editors to carry out appropriate fact-checking before publication.
My quibble is this. As I came to the book I knew very little about the aetiology and therapeutics of cancer. I was eager to hear what Mukherjee had to tell me about surgery, chemotherapy, radiotherapy, and the biology of carcinoma cells. Naturally, I was prepared to accept as authentic what he wrote on these topics. But every now and again, as he introduced some new technical term, he would tell us the purported etymology of the word in question. Now language is something I do know a bit about, and here almost everything Mukherjee says is inaccurate. This reduces my faith in him as an authority on other matters.
Marie Curie called the new element radium, from the Greek word for “light”.
No, radium is not Greek, and it does not mean ‘light’. The word was coined from rad- (in French radioactif) plus the suffix -ium (used to form the names of metallic elements). Rad- is from the Latin word radius, which means ‘rod, spoke, ray’. The Greek for ‘light’ is φῶς phōs (contracted from φάος phaos), stem φωτ- phōt-, which gives us photography, photon etc.
…vinca, the Latin word for “bind”.
No, the Latin word for ‘bind’ (verb) is vincio, vincire, vinxi, vinctum. The related noun is vinculum ‘a bond, fetter’. The form vinca is late Latin and botanical Latin for a genus of plants known in English as ‘periwinkle’. The drug vincristine was derived from a plant formerly included in the genus Vinca (but now placed in Catharanthus).
adjuvant, from the Latin phrase “to help”
No, the Latin origin of this word is adjuvans, with stem adjuvant-. It is not a phrase, but a single word. It means ‘helping’ and is the present participle active of the verb adjuvo. ‘To help’ is adjuvare, its infinitive.
[a propos Ramazzini’s De Morbis Artificum Diatriba] …one such morbis…
The intended word is morbus, the nominative singular of the word meaning ‘disease’. The form morbis is the Latin ablative plural, used after the preposition de.
mitosis — Greek for “thread” —
The Greek for ‘thread’ is mitos (μίτος). Mitosis is a modern Latin coinage based on this root.
Not about language, but a matter of general knowledge, is …the isolated hamlet of Brno, Austria…
Brno, where Mendel carried out his pea experiments at St Thomas’s Abbey, is no “isolated hamlet”, but a large city, the capital of Moravia.
I’m not saying that Mukherjee ought to have known all these things. I’m saying that someone — either the author or the publisher’s editor — ought to have checked the facts, which are readily available.
 I find it really depressing that announcers on our most popular classical music station, Classic FM, have so little idea how to pronounce foreign languages. Surely anyone concerned with classical music needs at least a smidgin of awareness of the phonetics (reading rules) of Italian? And of German, too, I’d have thought.
I find it really depressing that announcers on our most popular classical music station, Classic FM, have so little idea how to pronounce foreign languages. Surely anyone concerned with classical music needs at least a smidgin of awareness of the phonetics (reading rules) of Italian? And of German, too, I’d have thought.
A currently popular record album bears the title Il progetto Vivaldi 2. The Classic FM presenter called it ˈɪɫ prəˈɡetəʊ vɪˈvældi ˈtuː. I can see that it’s unreasonable to expect an educated Englishman to know the Italian for ‘2’ (due), but can’t everyone see that progetto is the Italian equivalent of the English word project and, like it, has dʒ?
There’s a classical ensemble called Gli Incogniti (‘the unknown people’). How do you think the Classic FM announcer pronounces this difficult name? That’s right, ˈɡliː ɪŋkɒɡˈniːti . Perhaps he thinks gli is related to the English word glee. (It’s actually the form the Italian plural definite article takes before a vowel, and in Italian gl stands for a palatal lateral.) OK, I know we do tend to anglicize incognito with penultimate stress, but in Italian the stress is actually antepenultimate. To the best of my knowledge, the Italian pronunciation of the ensemble’s name is ʎi iŋˈkɔɲɲiti. There's a video of them here.
In other news, a recent contestant on the TV panel game University Challenge referred to Descartes as ˈdeɪkɑː, which is taking the deletion of French final consonants too far. In French, he's dekaʁt(ə).
But I salute our choirmaster’s skill in anglicizing Italian musical terms during a recent practice. When we come to the ækəˈpeləri bit, I want you all to…
That’s an adjective formed by suffixing -y to a cappella, with word-internal intrusive r.
Rant over. Happy Christmas, everyone. Enjoy the music. Next blog: 27 Dec.
 Following on from yesterday’s blog…
Following on from yesterday’s blog…
As I put it to Michael, there is in each case also an optional variant involving schwa plus a nonsyllabic consonant.
— to which he replied that he didn’t know what I meant.
I’m not sure how to put it more clearly. I mean that although the word hidden, for example, is mostly pronounced ˈhɪdn̩, it can also be said as ˈhɪdən. Most cases of n̩ can be replaced by ən, and vice versa, with no change of meaning. And the same applies to the other syllabic consonants of English. You can say əl instead of l̩ in medal - meddle (though that might sound odd or childish, depending on where you come from). For hesitant you can say ˈhezɪtənt or ˈhezɪtn̩t. For blossom you can say ˈblɒsəm or ˈblɒsm̩. For gathering you can say ˈɡæðərɪŋ or ˈɡæðr̩ɪŋ (= ˈɡæðɚɪŋ), or indeed compressed as ˈɡæðrɪŋ.
In terms of phonology, I would say that syllabic consonants are not phonemes, i.e. not part of our underlying sound system. Rather, they are derived by rule from an underlying string of ə plus a non-syllabic sonorant consonant. I call the rule Syllabic Consonant Formation, and it takes the general form
ə [+son] → [+syll] / …
Two segments are reduced to one, with the sonorant consonant retaining its various attributes (place, nasality/laterality, etc) as it acquires syllabicity.
The conditioning environment of the rule (shown here just as “…”) is pretty complex. It varies according to different accents and different speaking styles, and also depending on which consonant is concerned. For ən after a strong vowel plus d, as in garden, the rule is strongly favoured (though evidently now becoming less so in some BrE). With a preceding fricative, as in lesson, it is still favoured, though perhaps less strongly. With an affricate, as in kitchen, it is disfavoured. In common and lion, i.e. after a nasal or a vowel, it is so strongly disfavoured as to be virtually unknown in RP-style English. Although a syllabic nasal following a nasal is a no-no, a syllabic lateral, on the other hand, is fine: channel ˈtʃænl̩.
Although the AmE NURSE vowel could in principle be analysed as a strong (= stressable) syllabic r̩, this would not fit the above rule, which requires a weak ə as part of the input. So I treat the NURSE vowel in both BrE and AmE as a primitive, ɜː ~ ɝː. The second vowel of AmE father, however, does fit, and I analyse it accordingly: ˈfɑːðər → ˈfɑːðɚ.
This is the reasoning behind the notation I use in LPD, where potential syllabic consonants are shown either as əl ən ər əm or as əl ən ər əm, depending on whether a syllabic consonant is more or less likely as the output. The LPD notational convention is that a raised symbol denotes a possible insertion, an italic symbol a possible omission. So ən implies a default n̩, as in hidden ˈhɪd ən → ˈhɪdn̩, while ən implies a default ən, as in hesitant ˈhez ɪt ənt → ˈhezɪtənt.
* * *
Here by request is a quick-and-dirty video of me saying ˈhɪdn̩ ˈhɪdən ˈmedl̩ ˈmedəl. Sorry about the poor sound quality.
 We usually exemplify the syllabic consonants of English with words that end in one, e.g. muddle ˈmʌdl̩, hidden ˈhɪdn̩.
We usually exemplify the syllabic consonants of English with words that end in one, e.g. muddle ˈmʌdl̩, hidden ˈhɪdn̩.
Michael Rodeno asked Is it possible to find syllabic sounds l, r, n, m in the middle or at the beginning of words?
Actually, if he’d consulted LPD he’d have seen that there I intentionally chose to illustrate the Syllabic Consonants article (p. 799) with the word suddenly ˈsʌd n li, which has a syllabic n̩ in the middle of a word.
There are plenty of other words with medial l̩ or n̩: think sandals, muddled, saddleback, Middleton, battlefield, rattlesnake, vitally; frightened, gardens, woodenly, hadn’t, mightn’t, ardent, woodentop, Attenborough, Hottentot, gluttony, Gordonstoun, as well as the uncompressed versions of rattling, dawdling, Madeleine, Middleham, fattening, gardening, Tottenham, Sydenham etc.
A more useful way of describing the restricted distribution of syllabic consonants is not by reference to their position in the word, but by reference to their relationship to strong (= stressable) syllables: syllabic consonants typically follow them. That explains why syllabic consonants never occur in initial position in words in isolation.
For syllabic consonants in initial position, all I can offer are cases such as had a lot, had another if pronounced with no schwa, i.e. as hædl̩ɒt, hædn̩ʌðə. You readily get this in connected speech: I started early, because I had a lot to do before lunch. So I had another coffee and got cracking.
Is that ɡʊd n̩ʌf?
Syllabic consonants are never categorically required in English. There is always an alternative pronunciation available, with ə and a nonsyllabic consonant.
More on this topic tomorrow.
 The news media tell us that the recently deceased Dear Leader of North Korea, Kim Jong-il, will be succeeded by his third son, Kim Jong-un. On radio and TV I have heard this name pronounced either as kɪm dʒɒŋ ʊn or as kɪm dʒɒŋ ʌn. Which is better?
The news media tell us that the recently deceased Dear Leader of North Korea, Kim Jong-il, will be succeeded by his third son, Kim Jong-un. On radio and TV I have heard this name pronounced either as kɪm dʒɒŋ ʊn or as kɪm dʒɒŋ ʌn. Which is better?
In hangul it is spelt 김정은. In the Revised Romanization system, now official in South Korea, this transliterates as Gim Jeong-eun, or in the McCune-Reischauer system as Kim Chŏng-ŭn.
So the romanization “Kim Jong-Un” accords with neither system.
Given the Korean spelling 김정은, we expect the pronunciation ɡ̊im d̥ʑ̥̯̯ʌŋ ɯn. The vowels in the last two syllables are back and unrounded. The first, spelt ㅓ and conventionally shown in IPA as ʌ, tends to sound to British ears more like ɒ, despite being unrounded. So pronouncing J(e)ong in English (BrE) as dʒɒŋ (rather than dʒʌŋ) seems a good idea.
The vowel in the last syllable is more problematic. Spelt ㅡ, and represented in IPA as ɯ, this is a vowel quality (close back unrounded) that appears exotic to us and for which we have no equivalent. Pronouncing it as English ʌ is wrong, since that is the sound we use for ㅓ. Using English uː would be inaccurate, since that is the sound we use for Korean ㅜ (as in the last syllable of 반기문 Ban Ki-moon). So I would vote for ʊ as the nearest English equivalent, giving kɪm dʒɒŋ ʊn as the best way of anglicizing this name, at least for BrE.
Here's the Guardian's cartoon. 
 On arrival in Poland we were kindly met at Warsaw airport by a colleague from Łódź, Przemek Ostalski. Once loaded up into his car, we had to find our way out of the multistorey carpark. This was not a straightforward task. We had to look for the signs saying WYJAZD and helpfully also in English, WAY OUT. (Note to Americans: that’s the BrE for ‘exit’.)
On arrival in Poland we were kindly met at Warsaw airport by a colleague from Łódź, Przemek Ostalski. Once loaded up into his car, we had to find our way out of the multistorey carpark. This was not a straightforward task. We had to look for the signs saying WYJAZD and helpfully also in English, WAY OUT. (Note to Americans: that’s the BrE for ‘exit’.)

I reflected on the importance in Polish of distinguishing between wyjazd ˈvɨjast and the very similar wjazd vjast, ‘entrance’: one letter difference, one phonetic segment difference, but just the opposite meaning.
 Rather more common in public signage, it seems to me, is another pair, equally confusing: wejście ˈvejɕtɕe ‘entrance’ and wyjście ˈvɨjɕtɕe ‘exit’. Many buses have two doors, one marked wejście and the other marked wyjście.
Rather more common in public signage, it seems to me, is another pair, equally confusing: wejście ˈvejɕtɕe ‘entrance’ and wyjście ˈvɨjɕtɕe ‘exit’. Many buses have two doors, one marked wejście and the other marked wyjście.  These two words differ by just one letter in seven, just one phonetic segment in seven (or six, if you count an affricate as only one segment). Native speakers, of course, take in their stride what looks to outsiders like a stupid design flaw in the language.
These two words differ by just one letter in seven, just one phonetic segment in seven (or six, if you count an affricate as only one segment). Native speakers, of course, take in their stride what looks to outsiders like a stupid design flaw in the language.
It does mean, however, that any speaker of Polish has got to be fully sensitive to the difference between e and ɨ. That includes NNSs trying to get their tongues around the language (blog, 7 July 2010: note that on that occasion the hamfisted respelling supplied to us for omijajcie góry, lasy, doły was ‘o-me-yaiy-che goo-reh laseh doeweh’, ignoring just this contrast).
What is even more interesting in this connection is something I have noticed about Polish /e/. This vowel is often transcribed more narrowly as ɛ, but I am wondering if an even narrower symbol ɛ̈ might be appropriate. It strikes me as often being considerably centralized. I’ve noticed this particularly in the final vowel of the placename Katowice, which tends to sound closer to English ə than to English e or eɪ. I got a helpful informant to pronounce jeszcze dziesięć ‘ten more’ — yes, ˈjɛ̈ʂtʂɛ̈ ˈdʑɛ̈ɕɛ̈ɲtɕ.
 However, Jassem’s Polish vowel chart (reproduced here from Wikipedia) shows the vowel as fully peripheral. The Wikipedia article makes no mention of possible centralization. Likewise Biedrzycki, in his Abriß der polnischen Phonetik (1974), plots this vowel as coinciding with cardinal 3 and comments merely (p. 60)
However, Jassem’s Polish vowel chart (reproduced here from Wikipedia) shows the vowel as fully peripheral. The Wikipedia article makes no mention of possible centralization. Likewise Biedrzycki, in his Abriß der polnischen Phonetik (1974), plots this vowel as coinciding with cardinal 3 and comments merely (p. 60) Das polnische Phoneme /ɛ/ wird hauptsächlich durch den vorderen halboffenen ungerundeten Vokal [ɛ] repräsentiert… Dieser Laut erinnert an das deutsche kurze [ɛ] in /bɛt/ Bett. The Polish /ɛ/ phoneme is mainly realized as the front half-open unrounded vowel [ɛ]… this vowel is reminiscent of the German short [ɛ] in Bett.
This centralization, if I am right about it, must make the wyjście — wejście distinction even harder to hear.
If you’re employed by the BBC, or work for an independent programme maker producing BBC programmes, then you are entitled to consult the BBC Pronunciation Unit for “professional advice about pronunciations in all languages”.
The staff of the Unit are all multilingual trained phoneticians, and do an excellent job.
Their advice covers anything from what, in a British context, might be called recherché and exotic… ...through the not-quite-so-exotic...
...through the not-quite-so-exotic... ...to names you’d think most educated BrE NSs would be familiar with (though presumably someone had asked).
...to names you’d think most educated BrE NSs would be familiar with (though presumably someone had asked).  (That should, of course, be Oxford, not Cambridge.)
(That should, of course, be Oxford, not Cambridge.)
As you can see, their indications of pronunciation do not include IPA transcriptions, but do offer a choice of two respelling systems.
One, “BBC Modified Spelling”, has been in use for many years. Some of the symbols it uses have diacritics: ī for the vowel of PRICE, ō for the vowel of GOAT, and oo with a breve (not available in Unicode) for the vowel of FOOT; breves are also used on ă ĕ ĭ ŏ ŭ to represent schwa. The voiced dental fricative is shown by underlining, th, and underlining is also used for the digraphs zh (IPA ʒ) and hl (IPA ɬ). Stress is shown by a superscript acute mark.
The other scheme is a newer one. It avoids diacritics, but at the expense of being perhaps less transparent. The letter y is used in two different senses, representing in some cases the PRICE vowel and in others the palatal glide. PRICE can also be written igh. Schwa is written uh or uhr. Stress is shown by capitalization.
Symbols that might be open to interpretation are accompanied by a brief explanation. 
Respelling systems based on orthographic conventions have one great advantage over IPA or IPA-style transcription systems. They are less phonetically explicit, more abstract. Instead of worrying about whether GOAT has a diphthong with a rounded first element (oʊ), a diphthong with an unrounded first element (əʊ) or a monophthong (oː), we just agree that ō (or oh) stands for whatever vowel you use in GOAT words.
However, respelling systems for English face particular difficulty in finding satisfactory symbols for
• the PRICE vowel, for which neither y nor igh is unambiguous, while ī has a diacritic
• the MOUTH vowel, for which both ou and ow are ambiguous (cf. soul, show)
• the GOAT vowel, for which oh may wrongly suggest a short vowel and oa, ou, ow are ambiguous (cf. broad, loud, now)
• schwa. If oh represents a long vowel, how can we make it clear that uh represents a short weak one?
_ _ _
This blog will now be suspended for a week. (I may see some of you in Łódź.) Next posting: 19 December.
 Timo Partanen writes from Finland commenting on what he thinks are ejective varieties of English /k/ that he has noticed in the speech of some native speakers. In particular he mentions a snooker player interviewed on YouTube, Judd Trump (listen here).
Timo Partanen writes from Finland commenting on what he thinks are ejective varieties of English /k/ that he has noticed in the speech of some native speakers. In particular he mentions a snooker player interviewed on YouTube, Judd Trump (listen here).
Mr Trump comes from Bristol, though I must say his accent doesn’t sound stereotypically Bristolian. In this clip he produces several striking, noisy, and somewhat palatalized velar ejectives for k when before a pause. Notice think at about 2:00 and again at about 3:09, and back at 2:50 and more strikingly at 3:20.
Timo asks Is this phenomenon to be analysed as ejectives, evidently developed from plosive aspiration, or have I made a mistake? Might this be characteristic of British English, perhaps of some of its particular dialects?
Good question. What’s the answer?
• The segments in question do indeed appear to be ejective, i.e. produced with an airstream mechanism that is glottalic rather than the usual pulmonic.
• Rather than having developed directly from aspirated plosives, I would say that kʼ developed from the glottal reinforcement that is frequently found with English voiceless plosives and affricates in this environment. Reinforcement involves making a glottal closure just before the oral closure and overlapping in time with it, ʔp ʔt ʔtʃ ʔk. If the glottal closure is held until after the oral release, it masks the latter, giving Cantonese-style no-audible-release plosives pʔ tʔ tʃʔ kʔ. If it is held throughout the oral articulation, ʔpʔ ʔtʔ ʔtʃʔ ʔkʔ, the further step of raising the glottis to compress the air in the oral cavity is straightforward: pʼ tʼ tʃʼ kʼ.
• Yes, it is characteristic of some British English. I don’t think anyone really knows just who does it and who doesn’t. Cruttenden mentions it several times in his revision of Gimson’s Pronunciation of English, claiming (p. 167 in the 7th edition) that it is rather more common in some dialects (e.g. South-East Lancashire) than in RP.
I discussed this matter briefly in my Accents of English (1982), where I wrote (vol. 1, p. 261) Preglottalization is not particularly associated with the south of England rather than the north. Indeed, my subjective impression is that in [the prepausal] environment it is at least as common in northern accents as in southern (thus [stɒʔp, kwaɪʔt, lʊʔk]). An emphatic articulation of the glottal component will readily convert this into an ejective, thus [stɒpʼ, kwaɪtʼ, lʊkʼ]; both northerners and southerners may be found who use these forms under appropriate stylistic conditions.
When explaining ejectives in Practical Phonetics (Pitman, 1971), I said (p. 3) Some people use ejectives in English when words ending in p, t, k, or tʃ … come at the ends of sentences.
The ejective variants do seem to be confined to pre-pausal position: you don’t get them in the middle of a fluent utterance. They are occasional, optional variants of the usual pulmonic stops. Impressionistically, ejectives are more frequent with k than with p, t, or tʃ, but that may just be because the two words think and back are particularly frequent in pre-pausal position.
Graham Pointon wrote on the topic in his blog some years ago. He thinks it’s a rather recent phenomenon. I wonder.
I had a phone call yesterday from a BBC local radio station, wanting me to comment on the shock-horror news that Camden Council had erected a sign saying “Coroners Court”, with no apostrophe. 
I wasn’t terribly keen to accept the invitation. Local radio interviews are time-consuming, have a small audience, and are unpaid. Nevertheless I chatted for a short while with the production assistant. In our conversation I took my usual line (blogs, 17 May 2011 and 3-6 Oct 2008), saying I didn’t really think that missing apostrophes were a matter worth getting hot under the collar about, and that in this case there was anyhow some question about whether it needed an apostrophe, and — if it did — whether it should go before or after the s. It would really be better if we abolished all possessive apostrophes.
The production assistant was dismayed at my reaction. She had me down as a stickler for orthographic accuracy, a defender of supposedly fixed rules. She was hoping that I would forthrightly condemn the Council’s illiteracy. When she realized that I wasn’t going to do so, she brought the conversation to a close and said they would look for someone else to comment on the matter.
 That was fine with me. It does, though, demonstrate the point that radio producers often have an agenda. If you’re not going to go along with that agenda, they may not want to interview you after all.
That was fine with me. It does, though, demonstrate the point that radio producers often have an agenda. If you’re not going to go along with that agenda, they may not want to interview you after all.
The case of Coroner’s/Coroners’/Coroners Court is not unambiguously clear-cut. We do indeed normally write Coroner’s Court, because each court has just one Coroner. Or do some such courts have two or more coroners? If so, the court in question would be a Coroners’ Court. And what is the plural? With several courts, there are presumably several coroners, which justifies the spelling Coroners’ Courts: is Coroner’s Courts OK too?

In the case of the Coroners’ Courts Support Service (pictured: note the two apostrophes) I suppose you could actually argue for Coroners’ Courts’ Support Service. In the other direction, I note that the webpage of the Coroners’ Society has a link to the Coroners’ Court [sic] Support Service.
It reminds me of the inconsistent naming of London tube stations, where the station after Earl’s Court as you go towards Heathrow is Barons Court (no apostrophe). King’s Cross is supposed to have an apostrophe, but not Colliers Wood or Golders Green.
Even when wielding an editor’s blue pencil, where I do try to ensure correct use of apostrophes, I wouldn’t change Sports Day to Sport’s Day or Sports’ Day — would you? I’m really not sure where to put the apostrophe, if any, in Gardener’s/Gardeners’/Gardeners Question Time. In the same spirit, I can live with Coroners Court, too.
Several times recently I have noticed the newspapers referring to ‘slebs’, by which they mean ‘celebrities’. Duly on guard against the recency illusion that leads us to think things we’ve just noticed must therefore be new phenomena, I checked in the OED. I find that the first citation there is from 1996, so a good fifteen years ago. 
Shortening a word in colloquial speech is nothing new. Compare bus, phone, mic, etc., and also street cred (credibility) and now peep(s) (people). But what I want to discuss here is the loss of the schwa from səˈleb(rəti) (= DJ’s sɪˈlebrɪtɪ): the word is shortened not to its bare stressed syllable leb, but to sleb.
Most cases of compression involving schwa loss are found in the phonetic environment of a following liquid plus a WEAK vowel, as in historically hɪˈstɒrɪk(ə)li, camera ˈkæm(ə)rə, factory ˈfækt(ə)ri. Hence we regularly find compression in the adjectives moderate ˈmɒd(ə)rət and separate ˈsep(ə)rət, with their weak-vowelled suffix, but not in the related verbs to moderate ˈmɒdəreɪt and to separate ˈsepəreɪt, where the phonetic environment is a following STRONG vowel.
So what we have in ‘sleb’ is not mainstream compression, because the vowel in -ˈleb- is strong. Comparable examples that spring to mind are the colloquial possible loss of schwa in terrific təˈrɪfɪk ~ ˈtrɪfɪk, colossal kəˈlɒsl̩ ~ ˈklɒsl̩, correct kəˈrekt ~ krekt, and perhaps pəˈhæps ~ præps (OED p’raps dated 1745). I can’t recall seeing any discussion of this in writing anywhere, though it’s something I’ve talked about in practical phonetics classes often enough. (There's probably something in Gillian Brown or Linda Shockey’s books on the phonetics of colloquial English.)  In the rough-and-tumble of rapid conversational speech I suspect that this reduction can be found for any word with the initial string obstruent—schwa—liquid. But it is presumably much rarer in words such as career, collide, forensic, giraffe, Goliath, Jurassic, Korean, peruse, salacious than in the everyday words mentioned in the previous paragraph.
In the rough-and-tumble of rapid conversational speech I suspect that this reduction can be found for any word with the initial string obstruent—schwa—liquid. But it is presumably much rarer in words such as career, collide, forensic, giraffe, Goliath, Jurassic, Korean, peruse, salacious than in the everyday words mentioned in the previous paragraph.
Very occasionally the reduction becomes lexicalized, as for those speakers whose citation form for police is pliːs rather than pəˈliːs (or dialectal ˈpoʊliːs etc.). There’s also pram, from perambulator, for which the OED’s first citation is dated 1884. Usually, though, we remain aware of the difference in pronunciation in pairs such as plight – polite, crowed – corrode, Clyde – collide, even if we sometimes pronounce them identically.
 Commenting on my recent posting about Tokyo Sexwale (22 Nov), Roger Lass writes
Commenting on my recent posting about Tokyo Sexwale (22 Nov), Roger Lass writes
…You mention the ‘velar fricative’ in Afrikaans. I must say that in over 25 years here in contact with Afrikaans I've rarely heard one except in a few hyper-posh varieties, or occasionally (but rarely) before front vowels in an uncommon version of the German ‘ich/ach rule’. The normal reflex of the early Germanic voiced back fricative, spelled <g>, is virtually always uvular, either a fricative or especially in initial position before a stressed vowel a voiceless uvular trill. This falls in with the voiceless back fricative < IE *k, so uvulars in goed, nag. Very similar if not identical to what is often called /x/ in Dutch but is also uvular in most varieties.
Afrikaans generally does not palatalise this before front vowels, but keeps it uvular, as in my experience do standard Dutch and Yiddish. All are languages that have a uvular not velar fricative (in Yiddish of course only from Germanic and Slavic voiceless back fricatives). It appears that uvulars may not be sensitive to palatal influence because of tongue shape. I've also noticed that many varieties of German, more than not in my experience, have a not very noisy uvular but definitely not velar fricative for <ch>, which does palatalise. As I recall, but am open to correction, there are varieties of Swiss German with a uvular trill for <ch>, and they don't palatalise.
In SA English speakers saying Sexwale (as well as Afrikaans loans with the same segment) have a uvular. The same is true of English speakers, in America, the UK and SA with Yiddish loans having this segment.
Thanks, Roger, for these observations.
I’d like to add two points: one about transcriptional practice, one about the facts.
The 1949 IPA Principles booklet, from which I quoted a few lines in last Wednesday’s blog about a (30 Nov), also has this (p. 12-13): As with vowels, it is desirable to substitute more familiar consonant letters for less familiar ones, when such substitution can be made without causing ambiguity. … In accordance with [this] principle … the sound χ can generally be represented by the letter x. This cannot, however, be done in such languages as Eskimo or Kabardian, where the velar and uvular sounds occur as separate phonemes.
The 1949 booklet contains transcribed specimens of both Dutch and Afrikaans, both using the symbol x without further qualification.
Fifty years later, in the 1999 IPA Handbook, Carlos Gussenhoven says this about Dutch: Roughly south of a line Rotterdam-Nijmegen, which is marked by the rivers Rhine, Meuse and Waal, /x, ɣ/ are velar, while to the north the corresponding voiceless fricative is post-velar or uvular.
And let’s not forget that velar—uvular is a continuum rather than an either/or disjunction.
Erg goed!
 Judging by the correspondence I receive, many people still find it difficult to enter IPA symbols on their computers.
Judging by the correspondence I receive, many people still find it difficult to enter IPA symbols on their computers.
I have recently read favourable reports of a little keyboard programme called i2Speak, “an online Smart IPA Keyboard that lets you quickly type IPA phonetics without the need to memorize any symbol code.”
This is a clever and user-friendly free programme that you do not need to install on your computer: you just call up a web page. You use it to create your text, and then copy-and-paste the text to where you want to have it.
The web page places a virtual keyboard on your screen. You can switch between modes such as ‘Smart IPA’, ‘IPA English’, and ‘SAMPA English’, and also within each access special keyboards for ‘Vowels’, ‘Diphthongs’, ‘Non-pulmo[nic]’, ‘Supra[segmentals]’ and so on, some of them bearing labels with phonetic terminology (‘Plosive’, ‘Nasal’, ‘Trill’ etc.). You can select the font and the font size. When ready, you press ‘Copy’ to transfer the resulting character or text onto the clipboard.
I2speak, although admirable, is not without some strange quirks and faults.
• The characters ɕ and ʑ (alveolopalatal fricatives) can only be brought to the display panel both together, where you must then delete the one you don’t want.
• The tie bar in the labialvelar k͡p is in the wrong place, after the two alphabetic letters instead of straddling between them, giving kp͡.
• Under ‘ejectives’ you can enter p’ k’ s’ directly, but not t’; but there are two separate buttons for inserting just the ejective diacritic ’.
• Among the Diphthongs labelled “England” you will find ɒɪ and ɛə but not the ɔɪ and eə that most of us use. The diphthongs (sic) labelled ‘USA’ include ɛɪɚ, which I cannot offhand ever recall having seen used for mainstream AmE.
• You can choose among a number of different fonts, but for some reason Segoe UI is not one of them. Yet that is the font I prefer for general use, and the font in which this blog appears (providing you have it installed, which will be the case if you are using a recent version of Windows).
You cannot enter connected English phonetic text using the ‘smart IPA’ or the ‘IPA English’ keyboard without also using your mouse, because there is no setting in which a single keyboard setting contains both the phonetic characters that you need (such as ɒ ʊ ə θ ʒ ŋ) and the ordinary alphabetic characters (such as p t k f v s z). For comparison, with Mark Huckvale’s Unicode Phonetic Keyboard I can write a continuous phonetic text such as I published on Monday entirely from the physical alphanumeric keyboard, never needing to switch mode by using the mouse.
Neither i2Speak nor any other available keyboard device would enable you to enter a text with assorted non-IPA characters, such as we had in yesterday’s blog. For that I used good old MS Word, where for an unusual character you just enter the Unicode number, select it, and press Alt-x. I composed the whole of yesterday’s text in Word, then copied everything en bloc and pasted it into blogspot.
Yesterday’s posting called for the small-cap-A symbol. I coded it straightforwardly in HTML as <small>A</small>. But blogspot accepts far fewer HTML tags in comments than it does in postings, so Paul, commenting, successfully entered it as a distinct Unicode entity, U+1D00.
Many, though by no means all, alphabetic small capitals are available in the Unicode range 1D00 to 1D7F. This block is known as Phonetic Extensions, and carries the introductory note These are non-IPA phonetic extensions, mostly for the Uralic Phonetic Alphabet (UPA).
The small capitals, superscript, and subscript forms are for phonetic representations where style variations are semantically important.
For general text, use regular Latin, Greek or Cyrillic letters with markup instead.
 As well as small caps (ᴀ ᴁ ᴄ), superscripts (ᴬ ᴭ ᵃ) and a few subscripts (ᵢ ᵣ ᵤ), the block contains various other typographically interesting characters. (I have no idea what they are used for in the Uralic Phonetic Alphabet — though see here.)
As well as small caps (ᴀ ᴁ ᴄ), superscripts (ᴬ ᴭ ᵃ) and a few subscripts (ᵢ ᵣ ᵤ), the block contains various other typographically interesting characters. (I have no idea what they are used for in the Uralic Phonetic Alphabet — though see here.)
Here among the small caps you will find a ‘reversed N’, ᴎ, a sideways Ø (ᴓ) and a sideways ü (ᴞ). There is a ‘Latin letter voiced laryngeal spirant’ (ᴤ) and a ‘Latin letter ain’ (ᴥ).
Not everything here is from the UPA. There is also a special ligature ᵫ, which I can see appealing to English lexicographers who prefer respelling to proper phonetic symbols, as will ‘Latin small letter th with strikethrough’, ᵺ. There is also something called ‘insular g’, ᵹ, labelled ‘older Irish phonetic notation’.
 Although they are not official IPA symbols, users of IPA will be happy to find here the lax high vowel symbols ‘with stroke’, ᵻ ᵼ ᵾ ᵿ: two of these are used in the Oxford Dictionary of Pronunciation, though the first, ᵻ, bears the Unicode warning ‘used with different meanings by Americanists and Oxford dictionaries’.
Although they are not official IPA symbols, users of IPA will be happy to find here the lax high vowel symbols ‘with stroke’, ᵻ ᵼ ᵾ ᵿ: two of these are used in the Oxford Dictionary of Pronunciation, though the first, ᵻ, bears the Unicode warning ‘used with different meanings by Americanists and Oxford dictionaries’.
A further Unicode block, Phonetic Extensions Supplement (1D80 to 1DBF) covers various former IPA symbols from which recognition was withdrawn at the Kiel Convention in 1989: those for consonants with velarization ᵬ ᵭ ᵮ ᵯ ᵰ ᵱ ᵲ ᵳ ᵴ ᵵ ᵶ and palatalization ᶀ ᶁ ᶂ ᶃ ᶄ ᶅ ᶆ ᶇ ᶈ ᶉ ᶊ ᶋ ᶌ ᶍ ᶎ, and for both vowels and consonants with retroflexion ᶏ ᶐ ᶑ ᶒ ᶓ ᶔ ᶕ ᶖ ᶗ ᶘ ᶙ ᶚ. So we can now find in Unicode everything we might need in order to digitize the 1949 IPA Principles, Jones’s The Phoneme, and various English-language accounts of Russian phonetics.
Commenting on Monday’s blog, Wojciech made the surprising remark Re the symbol 'a' in IPA: I too find it strange that it's reserved for a phoneme which occurs so rarely in European languages (if it occurs at all). Whereas the common continental (and Northern English, methinks) 'a' has got to be transcribed 'ä'.
I say no it isn’t, and no it doesn’t.
The vowel a occurs extremely commonly in European languages (and of course in non-European languages). The Northern English TRAP vowel, too, is very satisfactorily represented by the symbol a, with no diacritics. The contrary claims reveal a basic misunderstanding of how phonetic symbols are used when we represent the phonemes of a language or language variety. Let’s see why.
 The symbol a is one of the set of symbols representing the ‘Cardinal Vowels’ i e ɛ a ɑ ɔ o u defined by Daniel Jones.
The symbol a is one of the set of symbols representing the ‘Cardinal Vowels’ i e ɛ a ɑ ɔ o u defined by Daniel Jones.
No language is actually spoken with cardinal vowels: they are idealized reference points not defined by what happens in any particular language. (They are, however, suspiciously similar to a subset of the vowels of standard French as spoken in Jones’s day — though the quality of French ɔ, at least, was and is considerably different from that of cardinal ɔ. In passing we may note that the articulatory-auditory theory behind Jones’s cardinal vowel scheme is no longer accepted.)
Rather, these symbols are used for vowels in the general area concerned. Like all IPA symbols, they allow some considerable leeway. A typical French e is not identical with a typical Italian e or a typical German e, although all share a general similarity and all can be characterized as unrounded, front, and close-mid (‘half-close’). Compare colour terms, where we happily refer to shades of crimson, scarlet, vermilion and so on all as ‘red’. We are dealing not with discrete entities but with points in a multidimensional continuum.
In those languages it so happens that the close-mid e is distinct from an open-mid (‘half-open’) ɛ. (This claim is subject to qualification: for many French speakers the choice of one or the other can be more or less predicted from the phonetic environment, although others distinguish e.g. les le from lait lɛ; not all Italians make the distinction between venti ‘twenty’ with e and venti ‘winds’ with ɛ; in German the vowel quality distinction is accompanied, in stressed syllables at least, by a length distinction.)
There are many other languages in which there is only one unrounded mid front vowel: they include Greek, Spanish, Serbian, and Japanese. Qualititatively this may lie anywhere between cardinal e and cardinal ɛ. In each case the appropriate symbol, though, is e. In the words of the 1949 IPA Principles booklet (§20), When a vowel is situated in an area designated by a non-roman letter, it is recommended that the nearest appropriate roman letter be substituted for it in ordinary broad transcriptions if that letter is not needed for any other purpose. For instance, if a language contains an ɛ but no e, it is recommended that the letter e be used to represent it. This is the case, for instance, in Japanese…
Similarly, the symbol a, which as a cardinal vowel symbol denotes an unrounded front open (low) vowel, is also appropriate to denote an unrounded open vowel of any degree of advancement (anywhere from fully ‘front’ to fully ‘back’) if that is the only open vowel in the language. This is the case in Spanish, Italian, Greek, Serbian, German, and Polish, to mention only a handful of European languages. It is also the case in thousands of other languages around the world.
In RP I say ðə kæt sæt ɒn ðə mæt. If I switch into northern (I was bidialectal as a child), I say ðə kat sat ɒnt mat. That’s how I would transcribe it. I’ll leave someone else to measure the formant values of my northern a to determine just how central it might be.
This is a live issue. The Council of the IPA, having previously failed to agree, is again debating the issue of whether to recognize an additional vowel symbol, A, to represent a quality between cardinals a and ɑ. I shall vote against.
The Guardian has a regular rubric in its Corrections and Clarifications column, Homophone Corner. Yesterday’s read as follows. This led me to wonder what proportion of NSs have illicit (illegal) and elicit (evoke) as categorical homophones. Most of us, for sure. But are there some who make the vowel of elicit tenser than that of illicit? And do they do this variably or categorically?
This led me to wonder what proportion of NSs have illicit (illegal) and elicit (evoke) as categorical homophones. Most of us, for sure. But are there some who make the vowel of elicit tenser than that of illicit? And do they do this variably or categorically?
I ask because this is relevant to the notation appropriate for the Latin prefix e- in English words. As you will be aware, for the third edition of LPD I simplified the notation for the unstressed prefixes be-, de-, pre-, re-, deciding to use the happY vowel i rather than enumerating mainstream ɪ plus variant iː. (In any case we still need the further variant with ə.) I really wasn’t sure whether to include the e- words in this, but eventually decided to.
 Even that decision left marginal cases that were difficult to decide, and for which I may with hindsight have made the wrong decision. Elect? Event? Eleven? Of course, the decision for each particular word must depend not on etymology but on whether there appear to be people who use the tenser vowel — hence the inclusion of eleven, which does certainly not contain Latin e-.
Even that decision left marginal cases that were difficult to decide, and for which I may with hindsight have made the wrong decision. Elect? Event? Eleven? Of course, the decision for each particular word must depend not on etymology but on whether there appear to be people who use the tenser vowel — hence the inclusion of eleven, which does certainly not contain Latin e-.
 It also means that the main pronunciation given for elicit, iˈlɪsɪt, looks different from that for its putative homophone illicit, ɪˈlɪsɪt, which clearly has no tense-vowel variant. (Compare the main prons for descent diˈsent and dissent dɪˈsent, which likewise are homophones for most speakers but I think not all.)
It also means that the main pronunciation given for elicit, iˈlɪsɪt, looks different from that for its putative homophone illicit, ɪˈlɪsɪt, which clearly has no tense-vowel variant. (Compare the main prons for descent diˈsent and dissent dɪˈsent, which likewise are homophones for most speakers but I think not all.)
For previous discussion of the general issue, see my blog for 29 Jan 2007.
kɪdɪŋ ɔː nɒt, ɪf ə kɒmənteɪtər ɒn fraɪdiz blɒɡ kleɪmz tu əv hæd dɪfɪkl̩ti prəʊsesɪŋ ðə hedlaɪn ðen ɪts haɪ taɪm wi hæd ənʌðər entri rɪtn̩ həʊlli ɪn fənetɪk trænskrɪpʃn̩. (ðə lɑːs sʌtʃ entri ɪn ðɪs blɒɡ wəz ɪn dʒuːn.)
 lɑːs naɪt aɪ pleɪd maɪ mələʊdiən ət ə seʃn̩ ɪn ə pʌb ɒn wɪmbl̩dən kɒmən, nɒt veri fɑː frəm weər aɪ lɪv. ðiːz seʃn̩z ə held wʌns ə mʌnθ ən ɔːɡənaɪzd baɪ ə ləʊkl̩ mɒrɪs saɪd.
lɑːs naɪt aɪ pleɪd maɪ mələʊdiən ət ə seʃn̩ ɪn ə pʌb ɒn wɪmbl̩dən kɒmən, nɒt veri fɑː frəm weər aɪ lɪv. ðiːz seʃn̩z ə held wʌns ə mʌnθ ən ɔːɡənaɪzd baɪ ə ləʊkl̩ mɒrɪs saɪd.
dʒʌst ʌndə twenti piːpl̩ tɜːnd ʌp fə ðə seʃn̩. ðeɪ ɪŋkluːdɪd θriː ʌðə mələʊdiən pleɪəz. ɪts ɔːlwɪz ɪntrəstɪŋ tə kəmpeə nəʊts. bifɔː wi stɑːtɪd, wʌn əv ðəm kaɪndli əlaʊd mi tə traɪ aʊt hɪz ɪnstrəmənt (mʌtʃ mɔːr ɪkspensɪv ðəm maɪn).
evriwʌn wəz siːtɪd əraʊnd teɪbl̩z ɪn ə smɔːl rʊm ɪn ðə pʌb (ðə snʌɡ). wʌns ðə seʃn̩ prɒpə wəz ʌndə weɪ, ðə fɔːmən (tʃeəmən) kɔːld ɒn iːtʃ pɑːtɪsɪpənt ɪn tɜːn tə liːd ə tjuːn ɔːr ə sɒŋ. ðə prəʊɡræm wəz ə mɪkstʃər əv ɪnstrəmentl̩ stʌf (fɪdl̩z, kɒnsətiːnə, maʊθ ɔːɡən, mələʊdiənz) ənd ʌnəkʌmpənid sɪŋɪŋ. tuː ruːlz əplaɪd, əz ɪz juːʒuəl ɪn pʌb seʃn̩z — nəʊ æmplɪfɪkeɪʃn̩ ən nəʊ pleɪɪŋ ɔː sɪŋɪŋ frəm ə rɪtn̩ skɔː.
ðə sɪŋəz sæŋ veəriəs fəʊk sɒŋz ən fəʊk-staɪl sɒŋz. wiː ɪnstrəmentl̩ɪss pleɪd ɪŋɡlɪʃ (ənd ʌðə) dɑːns tjuːnz. ðiːz ə tɪpɪkli θɜːti tuː bɑː riːlz, dʒɪɡz, hɔːnpaɪps ɔː wɔːltsɪz, wɪð ðə strʌktʃər AABB. ðə kənvenʃn̩ ɪz ðət ju pleɪ iːtʃ tjuːn θriː taɪmz θruː, ɡɪvɪŋ ʌðə pleɪəz taɪm tə pɪk ʌp ðə melədi ən dʒɔɪn ɪn ɪf ðeɪ kæn.
maɪ əʊn fɜːs kɒntrɪbjuːʃn̩ wəz ə raʊdi riːl kɔːld tʃaɪniːz breɪkdaʊn (Chinese Breakdown), wɪtʃ tə maɪ səpraɪz ði ʌðə pleɪəz dɪdn̩t nəʊ — ɪt wəz wʌn əv ðə steɪpl̩z əv ðə bænd aɪ juːs tə pleɪ ɪn fɔːti jɪəz əɡəʊ — fɒləʊb baɪ ðə krʊkɪd stəʊvpaɪp (Crooked Stovepipe). leɪtə, wem maɪ tɜːn keɪm raʊnd əɡen, aɪ pleɪd dʒesiz hɔːnpaɪp (Jessie’s Hornpipe), seɡweɪɪŋ ɪntə səʊldʒəz dʒɔɪ (Soldier’s Joy), wɪtʃ evriwʌn nəʊz.
In the talk on Multicultural London English that I recently gave in Japan, one of the things I mentioned was a tendency to simplify the phonetics of the indefinite and definite articles by reducing their allomorphic variation. My data came from Kerswill et al., ‘Contact, the feature pool and the speech community: The emergence of Multicultural London English’, Journal of Sociolinguistics 15/2, 2011: 151–196. I am well aware that MLE speakers are not the first NSs to fail to observe the rules that we teach EFL students for the pronunciation of the (that is, ðə before a consonant sound, ði in front of a vowel sound, plus the occasional strong form ðiː). Indeed, I make the point in the note I put in the relevant entry in LPD.
I am well aware that MLE speakers are not the first NSs to fail to observe the rules that we teach EFL students for the pronunciation of the (that is, ðə before a consonant sound, ði in front of a vowel sound, plus the occasional strong form ðiː). Indeed, I make the point in the note I put in the relevant entry in LPD. 
What seems to be true is that ðə plus hard attack before a word beginning with a vowel sound is more frequently heard in MLE than in, say, traditional Cockney or RP. But this is only an impression: I don’t think we have much in the way of hard statistical evidence. The sociolinguists may know its percentage incidence in MLE (see table below), but there’s not a lot of information available about other varieties.  I don’t think I ever say ðə ˈʔæpl̩ and so on myself. But I could be wrong.
I don’t think I ever say ðə ˈʔæpl̩ and so on myself. But I could be wrong.
 At the age of 18, as I was picking up German by staying with a family in northern Germany on a family exchange, I noticed that when wanting to know the time my exchange partner, rather than ask Wie viel Uhr ist es? (‘how many o’clock is it?’), as shown in my tourist’s phrasebook, would usually go for the formula Wie spät ist es? (‘how late is it?’). So I did so too.
At the age of 18, as I was picking up German by staying with a family in northern Germany on a family exchange, I noticed that when wanting to know the time my exchange partner, rather than ask Wie viel Uhr ist es? (‘how many o’clock is it?’), as shown in my tourist’s phrasebook, would usually go for the formula Wie spät ist es? (‘how late is it?’). So I did so too.
Imitating his pronunciation, I pronounced spät as ʃpeːt, using the same vowel sound as in Wie geht’s viː ˈɡeːts ‘how’s it going?’.
As I got to grips with the written as well as the spoken language, I learnt to treat the umlauted letter ä as being pronounced exactly the same as the letter e.
Years later, when I studied phonetics with John Trim at Cambridge, he told me that the German pronunciation I had acquired through total immersion, while commendably native-like in its way, was in some respects regional. If I wanted to speak proper Hochdeutsch, I ought to remember to say Guten Tag! with taːk, not ta(ː)x; the train, der Zug, should be tsuːk, not tsʊx; and for long ä, as in spät, I ought to add a new item to my German vowel system, namely the long ɛː, thus ʃpɛːt.
The standard set out in German dictionaries and textbooks treats orthographic e and ä as having the same value when short, ɛ, but different values when long, namely eː and ɛː respectively.
So fällen ‘to fell’ ˈfɛlən is a perfect rhyme for bellen ‘to bark’ ˈbɛlən (both have the short vowel). But wählen ‘to choose’ should not, in Hochdeutsch, be a perfect rhyme for fehlen ‘to be lacking’ (with the the long vowel): ˈvɛːlən, ˈfeːlən.
This distinction still feels artificial to me, and I don’t make it unless perhaps carefully reading some text aloud or making a phonetic point.
The pronunciation dictionaries tend to hedge their bets on this distinction. Here’s the sixth edition of the Duden Aussprachewörterbuch. Der Vokal [ɛː] kann auch [eː] gesprochen werden… (p. 21: ‘The vowel [ɛː] can also be pronounced [eː]…’)
And here’s the Deutsches Aussprachewörterbuch. Der Unterschied zwischen [eː] und [ɛː] wird in der Aussprache meist nich stark verdeutlicht, so dass häufig ein Vokalklang zwischen [eː] und [ɛː] mit einer Tendenz zu [eː] entsteht. (p. 58: ‘The difference between [eː] and [ɛː] is for the most part not made very clearly in pronunciation, so that frequently a vowel quality between [eː] and [ɛː] arises, with a tendency towards [eː].’)
Wikipedia says, I think quite correctly, The long open-mid front unrounded vowel [ɛː] is merged with the close-mid front unrounded vowel [eː] in many varieties of Standard German…
I shall continue to speak German with an undifferentiated eː.

One or two of the people commenting on nt-reduction (blog, 18 Nov.) also mentioned the possibility of twenty having the vowel ʌ.
Kensuke Nanjo said According to my daily observation of American English, I think this variant is worth including in pronouncing dictionaries. Quite a few Americans use it and as you may know, this is the second variant for "twenty" in the Merriam-Webster Collegiate Dictionary.
 There are indeed plenty (“plunny”?) of Americans who seem to pronounce twenty with a seriously backed and lowered quality as compared with their default DRESS vowel.
There are indeed plenty (“plunny”?) of Americans who seem to pronounce twenty with a seriously backed and lowered quality as compared with their default DRESS vowel.
However, in deciding whether this is a sporadic irregularity found just in this word (and perhaps in plenty too), we must first establish what is their default DRESS vowel. We need to discount the possible effects of what, following Labov, has come to be known as the Northern Cities Vowel Shift.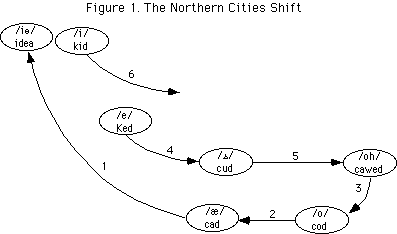
The “northern cities” (of America) in which this sound change flourishes are clustered around the Great Lakes: places such as Buffalo, Cleveland, Detroit, and Chicago. The geographical extent of the shift varies depending on which vowel is involved and in which phonetic environment(s); and in any case it is also socially and stylistically variable. But what it can do is to make DRESS words sound as if they have the STRUT vowel — perhaps all of them, perhaps particularly those in which the vowel is followed by a nasal. Note that the STRUT vowel shifts too, so that we do not normally get loss of the distinctions exemplified in get – gut, bed – bud, wren – run etc.
So someone who says ˈtwɛ̈ni, with a thoroughly retracted vowel, is not necessarily saying ˈtwʌni (“twunny”), to rhyme with funny.
Others, though, are. They include rirelan, who mentioned twenty: /ˈtwʌni/ (along with "plenty" /ˈplʌni/. "plentiful" is still /ˈplɛntəfəl/ though.)
Furthermore, Americans from other, mainly southern or western, parts of the country may merge pen and pin as pɪn (i.e. merge DRESS with KIT before a nasal). For them, twenty may rhyme, if not with funny, then with skinny as well as with many.
Kensuke reckons that a reasonably exhaustive pronunciation dictionary ought to give AmE twenty as ˈtwenti, ˈtwʌnti, ˈtweni, ˈtwʌni. Seems reasonable, though perhaps we ought to add ˈtwɪnti, ˈtwɪni, too.
 The egregious Sepp Blatter, president of FIFA, tried to defuse the impact of his recent inept remarks on tackling racism by getting the newspapers to print a picture of him in the company of Tokyo Sexwale, the black South African politician.
The egregious Sepp Blatter, president of FIFA, tried to defuse the impact of his recent inept remarks on tackling racism by getting the newspapers to print a picture of him in the company of Tokyo Sexwale, the black South African politician.
But how do we pronounce Mr Sexwale’s name? Certainly not ˈseksweɪl.
If you search on-line, you find no authoritative answer and several conflicting pieces of advice from amateurs.
An exchange on reddit went
● Spoiler: Tokyo Sexwale is not pronounced the way it's spelled.
● Yup. As my South African-parented girlfriend immediately pointed out, it's "Seh-tongueclick-wah-leh."
and then● The 'x' in the Sex part is pronounced like a soft 'g' in afrikaans.
Meanwhile the online Telegraph told us firmly Tokyo Sexwale (pronounced seh-wa-le)…
This is one of the names I decided to add to the most recent edition of LPD, so I actually checked it out a few years ago (blog, 3 July 2007).
My initial expectation was that the letter x in his name would stand for the voiceless lateral click, as it does in Xhosa and Zulu, where xoxa ‘tell’ is pronounced ˈǁɔːǁá (or, if you prefer greater explicitness in click symbolism, ˈk͡ǁɔːk͡ǁá).
However, my further researches seemed to suggest that Mr Sexwale’s ethnicity is not Xhosa or Zulu but Venda (or Venḓa — the diacritic indicates a dental, as opposed to alveolar, place of articulation). And in Tshivenḓa the letter x has its IPA value, representing a voiceless velar fricative. So he’d be seˈxwaːle.
The BBC Pronunciation Unit confirmed this. Yes, the IPA for our entry [for Sexwale] indicates a velar fricative. The recommendation is based on the advice of colleagues in Focus on Africa, who, according to our history note from 1993, were adamant that the orthographic 'x' is pronounced as a velar fricative.
(That is indeed also how the orthographic g of Afrikaans is pronounced.)
Conclusion: in English we should call him seˈxwɑːleɪ or, failing that, seˈkwɑːleɪ.
On Friday I said Maybe I’ve just not been keeping my eyes open, but I can’t recall reading any surveys of the prevalence or otherwise of what I would like to call nt-reduction.
 One resource I overlooked has now been brought to my attention by Kensuke Nanjo, phonetics editor of the Genius English-Japanese Dictionary, Fourth Edition (2006), in a long email which is worth quoting in extenso. He claims that this “G4” is
One resource I overlooked has now been brought to my attention by Kensuke Nanjo, phonetics editor of the Genius English-Japanese Dictionary, Fourth Edition (2006), in a long email which is worth quoting in extenso. He claims that this “G4” is
the only dictionary that distinguishes [nd] (t-voicing) and [n] (t-deletion) for underlying /nt/ in American English. G4 gives [nd] for carpenter, certainty, into, ninety, seventy, Washington as their second variant in American English while it shows variants without /t/ for other /nt/-words like center, dental, Internet, plenty, twenty, winter, etc. with the label "casual AmE".
Kensuke says that the decisions he made were
based on some books and papers that I'd read and personal communications with American phoneticians, perhaps including the late Becky Dauer, but I'm afraid I don't very well remember where I obtained the data. This distinction ([nd] vs. [n] for /nt/), however, is mentioned in the phonetics/phonology chapter I wrote for the book Ando & Sawada (eds.) English Linguistics: An Introduction (2001), so I obtained the data more than a decade ago.
He further comments
You rightly mention that "it does not happen in the environment of a following stressed vowel, as in intend, contain", but both LPD and G4 record /nt/-reduction for Antarctic, perhaps as a sole (?) exception.
— probably because of the transparent morphology which makes ant#arctic seem like a compound comparable to print#out, in which nt-reducers do reduce nt.
He continues Also, I agree with your comment that "[it doesn't] apply to ntr clusters, as in country. The t can be lost in centre/center but not in central", but G4 gives the variants like "inner"-duce and "inner"-duction for introduce and introduction respectively, with the label "casual AmE". This is based on my own daily observation about American English. Needless to say, this is a case of r-to-schwa metathesis, which triggers /nt/-reduction. In fact, I tried to include as many cases of common metathesis as possible in G4, so it gives the American casual pronunciation "hunnerd" for hundred, a case of both r-to-schwa metathesis and lexically restricted /nd/-reduction (e.g. can'idate, fun'amen'al, kin'a, un'erstand, won'erful).
These nd-reductions of casual speech are very relevant, too. Thanks, Kensuke.
Maybe I’ve just not been keeping my eyes open, but I can’t recall reading any surveys of the prevalence or otherwise of what I would like to call nt-reduction. By this I mean the loss of t from the cluster nt in intervocalic contexts. This makes winter a possible homophone of winner,
By this I mean the loss of t from the cluster nt in intervocalic contexts. This makes winter a possible homophone of winner,
painting a possible rhyme of straining and dental a potential rhyme of kennel. As far as I know this is not found in any kind of British speech, and we think of it as an American or Australian characteristic.
The possible AmE pronunciation of continental as ˌkɑ̃ːʔn̩ˈẽnl̩ is quite strikingly different from the BrE ˌkɒntɪˈnentl̩.
Several qualifications are needed.
• In the kind of AmE I am referring to, winter may possibly have a nasalized tap, thus ˈwɪɾ̃ɚ, rather than the more deliberate plain nasal of winner ˈwɪnɚ. Trager and Smith (1951) refer to this as a ‘flap-release short nasal’, how accurately I am not sure. In any case, a distinction based solely on ɾ̃ vs. n cannot be very robust. I suspect that in reality for many Americans (and Australians) winter and winner can be, and often are, pronounced identically.
• I have the impression that the incidence of nt-reduction is subject to regional variation in the US. It seems more prevalent in the south and west, less so in the north-east. Is this so? Do Canadians ever do it? It is also probably subject to stylistic variation, with unreduced nt more careful and the reduced variant more casual. Has anyone ever investigated its sociolinguistic characteristics?
• The environments in which nt-reduction operates seem to be the same as those for t-voicing. In particular, it does not happen in the environment of a following stressed vowel, as in intend, contain, nor of a following unstressed but strong vowel as in intake; nor does it apply to ntr clusters, as in country. The t can be lost in centre/center but not in central.
• Some words may be special cases, In particular, I have the impression that ninety in AmE is often ˈnaɪndi rather than the expected ˈnaɪnti or ˈnaɪni. Does the same apply to seventy? Are there other exceptional cases?
• Special cases of a different kind are the handful of words in which a similar reduction is found in BrE, namely in London and some other kinds of popular English. For Brits who do this, the t can be lost from twenty and plenty, and from prevocalic went and want (as in went out, wanted), but not from words such as winter or painting.
This posting was triggered by my hearing an Australian golf commentator on TV referring to ðə ˌsevn̩ˈiːnθ the seventeenth (hole). This violates the constraint barring nt-reduction before a stressed vowel, and I suspect would not be possible in AmE.
Furthermore, I wonder whether Australian English has taken nt-reduction direct from AmE, rather than via some British source? And if so, is it the first instance of such a sound change?
 Another interesting paper at the Łódź conference was given by Włodzimierz Sobkowiak (seen with me in this photograph, taken by Alice Henderson).
Another interesting paper at the Łódź conference was given by Włodzimierz Sobkowiak (seen with me in this photograph, taken by Alice Henderson). 





























